Plausible diffs are where expensive mistakes hide.
Over the last few months, I’ve been running a product stack end-to-end myself, with no review queue to hide behind when an AI hand-waves a gnarly edge case. For a while, my workflow was the default one: I’d describe a task to Claude, it would write the code, I’d skim the diff, and I’d merge. It worked. Mostly.
Then I started noticing the failure mode. The diffs all looked plausible. The tests mostly passed. But regressions would appear days later in places I hadn’t thought to check. The iOS client expected a field the Go handler had renamed. The web app silently degraded because a response shape had shifted.
The AI wasn’t wrong.
It was locally correct and globally unaccountable.
And I, the “reviewer,” was pattern-matching on “looks fine” instead of reading critically.
The real problem wasn’t whether AI could generate code. It was whether I could build a review system that preserved engineering judgment, created a durable audit trail, and held up under real operational pressure.
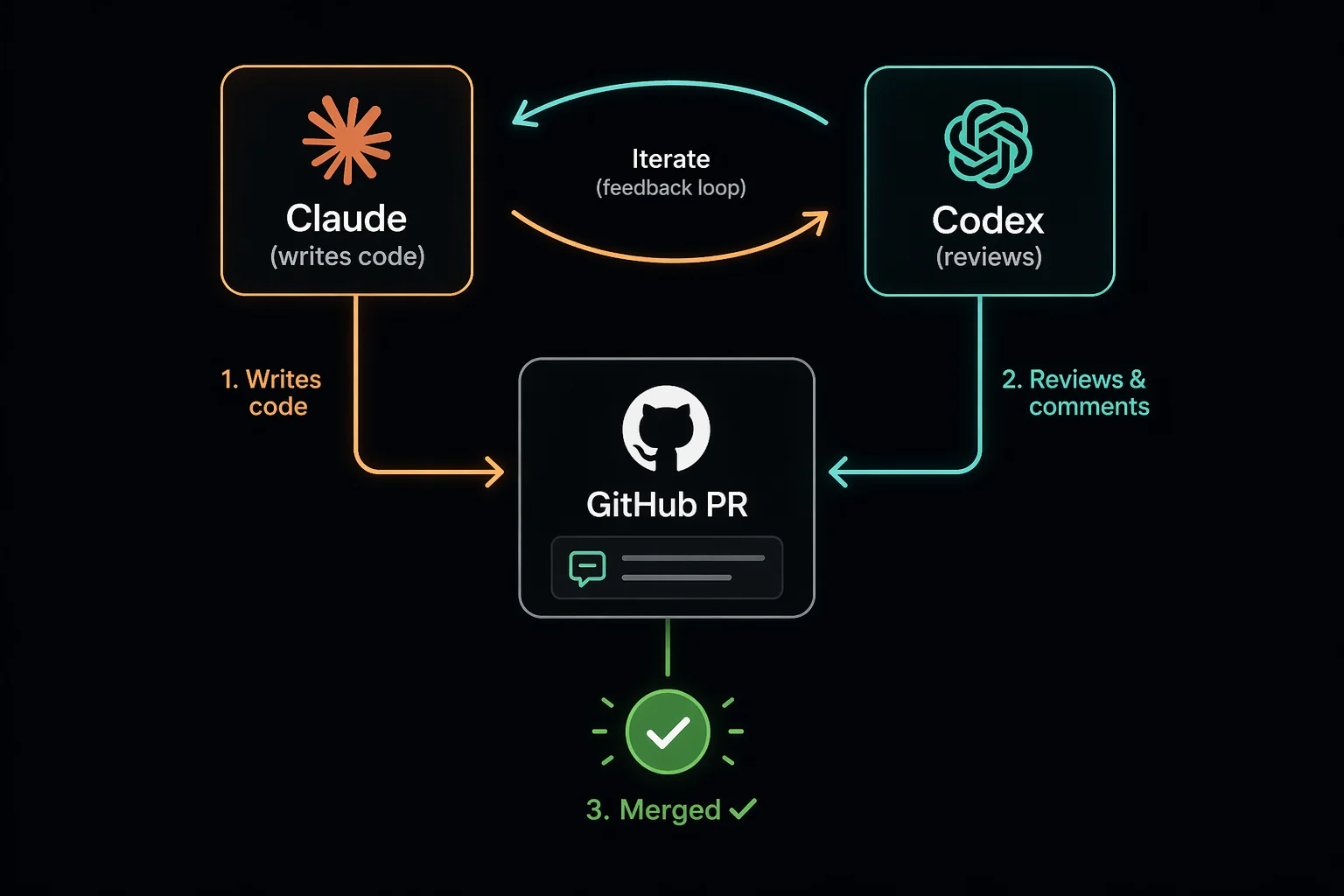
So I rebuilt the workflow around a single idea: every PR has to survive an argument between two AIs, and that argument has to live in the commit graph. I call this pattern Claudex.
This isn’t about better generation. It’s about forcing generated code to prove it’s safe to ship.
The problem with single-agent AI coding
Single-agent AI coding has three failure modes that are easy to miss when the human in the loop is also the person accountable for the outcome:
- The reviewer is the writer. If Claude wrote the code and I’m the only other reader, I’m reviewing against the same mental model that produced the diff. I rarely catch my own blind spots.
- Cross-surface drift. A full-stack product has a Go API, a Next.js web app, and iOS and Android clients. An AI writing one side of that contract will not reliably catch when it breaks the other three.
- No paper trail. When I “addressed feedback,” the feedback was a passing comment in a chat window. Three weeks later, I couldn’t tell you what I’d changed or why. The PR said “fix bug.” The commit said “fix bug.” The reasoning evaporated.
The relatively cheap fix to all three is to add an adversary and put its critique somewhere permanent.
The rules
The workflow is built around two rules:
- Two models, different vendors, on every PR. Claude (Anthropic) writes the code. Codex (OpenAI) reviews it. Using different vendors matters because same-family models can share blind spots. Different training data, different failure modes.
- Accountability lives in git, not in chat. Every critique the reviewer raises gets its own commit and its own PR comment. Not a squash. Not a hand-wavy “addressed in latest push.” One finding → one commit → one comment tying the commit back to the specific critique.
The first rule is about catching mistakes. The second is about making the process legible to future-me, to teammates or clients, and to anyone trying to understand why a change was safe to ship. The discipline of writing that comment forces me to understand what actually changed instead of waving it through.
The pipeline
Every task follows the same seven steps. They’re wired up as shell scripts so I never run raw git worktree or gh pr create by hand.
1. Isolate. A throwaway copy of the repo is created on a new branch, using a git worktree. The main checkout never gets modified. If the task goes sideways, I rm -rf the worktree and nothing else breaks.
2. Build. Claude investigates the relevant code, writes the change, runs the backend tests. All inside the sandbox.
3. Open the PR. A commit script stages files and writes a conventional-commit message. A push script creates the PR with a summary, evidence, and test plan. The script is idempotent. Later pushes just add commits to the open PR.
4. Adversarial review. Codex reviews the diff and posts its findings as a PR comment. This is the core adversary step.
Codex has never seen the chat that produced the code. It evaluates the diff cold.
5. Respond, with discipline. For each finding Codex raises, Claude makes one focused commit fixing it. The commit is named for the finding, e.g. fix: handle nil session in /me per codex review. Then it pushes and leaves a PR comment quoting the specific critique and pointing to the commit SHA. No squashing multiple fixes into one commit. No “addressed all feedback” catch-alls. One finding, one commit, one comment. If Claude disagrees with a finding, no commit, just a PR comment explaining why. That puts the disagreement on the record too.
6. Cross-surface smoke. After the review cycle settles, a smoke script boots the sandbox’s own backend on port 8080 and runs contract checks against it from the web app, the iOS app, and the Android app. Every client exercises the real API in the sandbox. This catches the drift-across-clients failure mode directly. If the Go handler changed a field name, the iOS contract check fails before the PR can merge.
7. Red smoke blocks the merge. Same rule as Codex findings: one smoke failure, one commit, one PR comment naming the suite that failed and the fix. Re-run until green.
The full loop, end to end on a real change, takes somewhere between 15 and 40 minutes of wall-clock time. Most of that is me reading the Codex review and the smoke logs rather than writing anything.
One representative cycle looked like this:
- Claude updated a backend response shape.
- Backend tests stayed green.
- Codex flagged that one mobile client was still decoding the old field name.
- The fix landed as a separate commit tied back to that exact review comment.
- The follow-up smoke run passed across web, iOS, and Android.
That’s the class of bug this loop is built to catch: changes that are perfectly plausible inside one surface and obviously wrong once the rest of the product touches them.
What actually changed
Three things, concretely:
Cross-client regressions were drastically reduced. Since I added the smoke step, API shape changes either make it through all four contract checks or get caught before merge. I haven’t seen the old class of bug where one client silently gets a null or a renamed field make it through this workflow.
PR history turned into a paper trail. I can read a PR from six weeks ago and reconstruct what the reviewer flagged, what I fixed, what I pushed back on, and why. The commits are small, the comments explain the thread, and nothing important lives in a chat window anymore.
My role shifted. I went from “the person who reads every diff line-by-line” to “the judge of the argument.” I read Codex’s review first, then Claude’s fixes, then the smoke output. In that order. If the argument looks thin (Codex missed something obvious, or Claude capitulated to a critique I disagree with), I intervene. Otherwise I stay out. It’s less work and, weirdly, I trust the output more.
What doesn’t work
Being honest about the limits:
- It’s slow for trivial changes. A one-line typo fix doesn’t need two AIs and a four-platform smoke. I run the full loop for anything touching core logic, API shape, or auth, and skip it for pure copy changes and config tweaks.
- It’s not free. Running a second frontier model on every PR and booting four client smokes per worktree costs real money. It’s cheap relative to production regressions, but it’s still a line item I watch.
- Codex isn’t gospel. It raises false flags, misunderstands context, sometimes pattern-matches to conventions this repo doesn’t use. The rule that Claude must either fix or argue, never silently ignore is what keeps this honest. If every Codex finding became a commit, the PRs would be bloated with noise.
- It doesn’t replace product judgment. Both models will happily build the wrong feature correctly. The adversarial loop catches implementation mistakes, not requirement mistakes. Those are still on me.
The pattern, if you want to try it
Strip away the project-specific bits and the transferable pattern is:
- Pick a second model from a different vendor than the one writing your code.
- Run it as an automated reviewer on every non-trivial PR.
- Enforce one-commit-per-finding with a PR comment tying each commit to the specific critique. Make it mechanical: a script, not a vibe.
- If your project has multiple client surfaces, boot the changed backend in isolation and run contract checks from every client before merge.
- Let disagreements go on the record as comments. Don’t silently ignore findings.
The productivity gain from single-agent AI coding was large and visible.
The gain from adding the adversary shows up in stability.
Cross-client regressions were drastically reduced. Contract drift gets caught before merge. A few months into running this loop, I have a PR history I can actually read, a test matrix that catches issues before users do, and a review process I trust more than single-agent generation.
If you’re responsible for shipping AI-assisted code and you’ve hit the “the AI keeps writing plausible but subtly wrong code and I don’t catch it” wall, try adding the adversary.
It changes what you catch. And what you stop shipping.